Before we moved to Amazon for digital-critical services we’d maintain banks of servers from Rackspace for clients with pockets (circa £600pm per server) and those that had smaller budgets or cared less we’d use co-locational servers from 1&1.
They’re fine, but not very good at staying up and tended to be rather support intensive – in fact, we used to have a full-time systems support guy costing circa £35k a year, bizarrely looking after £40 a month servers.
Strange, sometimes, the situations you find yourself in when legacy business decisions are evaluated using hind-sight.
We do still have a couple of clients still running on the cheapy servers and, no surprise, they’re the ones causing the most amount of grief and the most amount of downtime and sit squarely at the bottom (or top as the way this is sorted).
To protect the old and the infirm we’ve hidden the names, but the stability performance is quite marked.
To put this into context, some of the servers are Amazon Small instances costing less than £100 a month and appear to be outperforming a number of more expensive dedicated servers.
There are other choices for hosting and there are other cloud players on the block but Amazon is pretty tough to beat – assuming you’re not penny pinching (our Amazon bill run is now well past £5k). The game-stopper, for most, is legacy systems and a fear (or absence of experience) to move over.
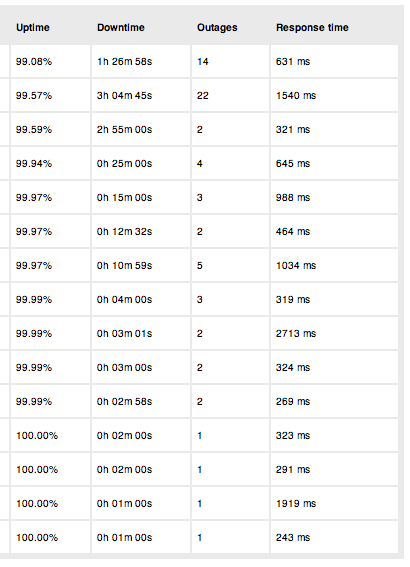
Listed are servers that experienced any downtime whatsoever during September. Numbers are rounded to 2 decimal places. Response times are measured using Pingdom and include the time to read defined content (usually a meta description) on a physical web-page. Cached services and CDN delivered content is excluded as it’s meaningless, in our opinion.